Many APIs are designed as simple collections of endpoints: they receive data, execute logic, and return a response.
This approach works in simple scenarios, but in real-world systems —billing, third-party integrations, automation workflows, or asynchronous processes— it quickly becomes insufficient and introduces structural issues.
The problem is not the API, it is the system design
An API should not be a set of exposed functions. It should be the entry point to a well-defined process.
When this is not considered, problems start to appear — often in production, when the system grows or integrates with other systems.
Common mistakes in API design
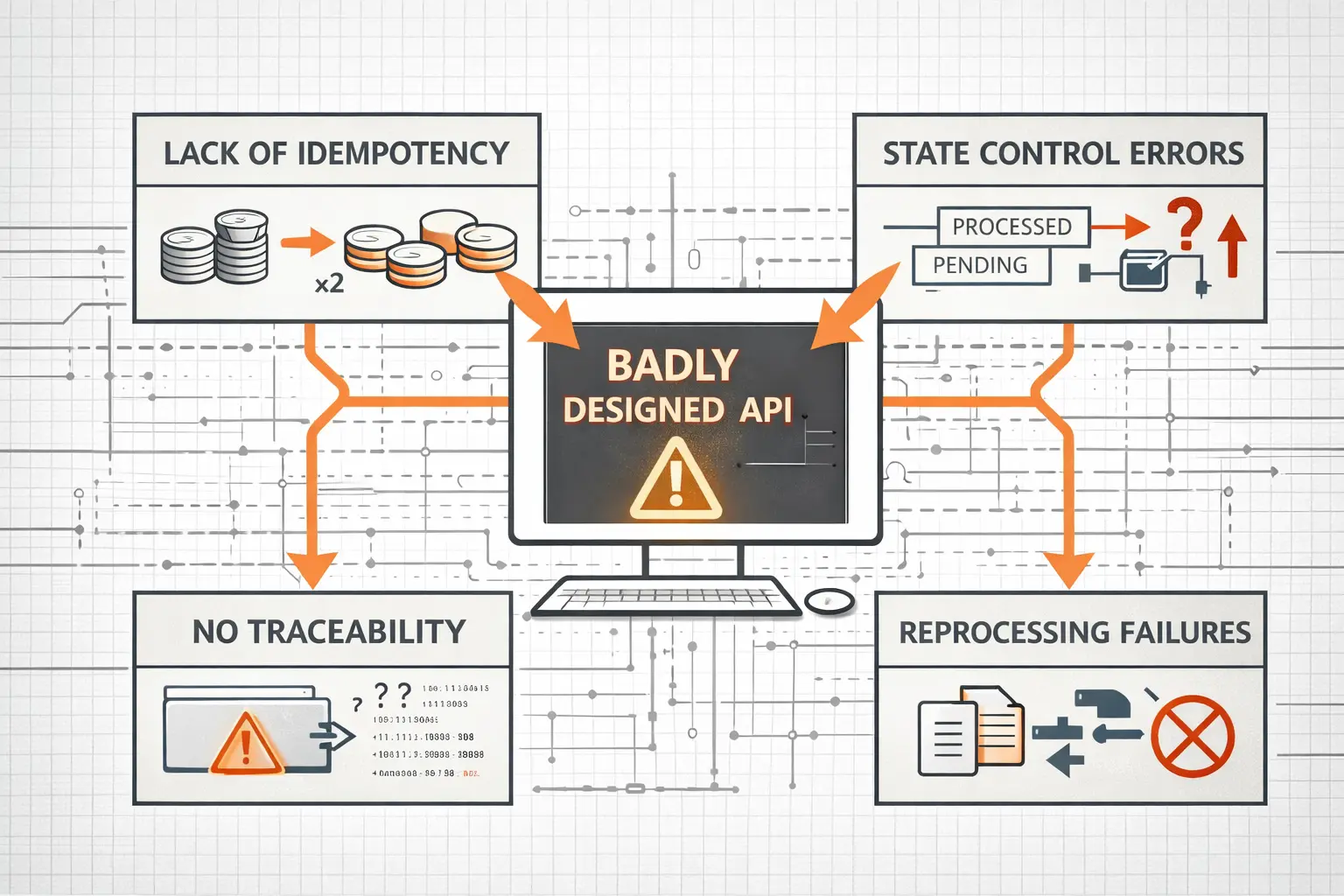
- Lack of idempotency
- No traceability (not knowing what actually happened)
- No state management
- No reprocessing capability
- Strong dependency on execution order
These issues are rarely visible at the beginning, but become critical over time.
Consequences in real systems
Poorly designed APIs lead to fragile systems:
- Hard-to-reproduce errors
- Duplicate operations
- Data inconsistencies
- Processes that fail without recovery options
In environments with external integrations or critical workflows, this becomes a serious operational risk.
A different approach: process-oriented APIs
At Intercyd, we follow a different approach: each API represents the entry point to a complete process.
This means that every request:
- Is fully logged (input and output)
- Has a defined state
- Can be reprocessed if needed
- Is fully auditable
The API is no longer just an execution point, but part of a larger system.
Idempotency and duplicate control
Idempotency is a key concept: ensuring that an operation can be executed multiple times without unintended side effects.
This is critical when:
- Automatic retries are involved
- External systems trigger requests
- The system does not fully control execution flow
Without idempotency, failures lead to inconsistencies that are hard to fix.
Process persistence in the database
Another key aspect is that the process does not live in the API code, but in the database.
This allows:
- Tracking every step of the process
- Managing intermediate states
- Allowing reprocessing
- Auditing the entire system
Once again, PostgreSQL becomes the core of the system, not just a storage layer.
Well-designed simplicity
This approach does not require complex architectures.
In many projects, we use a simple but powerful stack:
- Native PHP
- Nginx (routing and access control)
- PostgreSQL (logic and persistence)
The key is not the stack, but the system design.
When this approach makes a difference
This model is especially useful when:
- There are third-party integrations
- Processes are critical (billing, payments, onboarding, etc.)
- Full traceability is required
- The system must be resilient to failures
Conclusion
An API should not be limited to executing code. It should be part of a system designed to be predictable, auditable, and resilient.
The real value is not in the endpoints, but in the process behind them.