The most common mistake in document AI projects is assuming that the problem is simply “reading” the document.
OCR, automatic parsing, or sending entire files directly to a language model are often the first approaches considered. However, in real-world systems, this is not enough—and in many cases, it is the wrong approach.
The problem is not reading documents. The problem is turning them into reliable, structured, and usable data.
The real challenge: heterogeneous documents
In real environments, documents do not follow a single format or structure. A single workflow may include:
- Native PDFs with structured text
- Scanned PDFs without text layers
- Images
- Excel files with varying structures
- Word documents with semi-structured content
Applying a single approach to all of these formats leads to errors, loss of context, and unnecessary cost.
Why many document AI approaches fail
A common pattern is sending entire documents directly to a language model expecting structured JSON as output.
This approach introduces several problems:
- High token usage and cost
- Lack of control over analyzed content
- Inconsistent results across documents
- Difficult debugging and validation
AI becomes a black box, limiting the ability to build reliable systems.
A pipeline-based approach
At Intercyd, we follow a different approach: AI is not the first step, it is the last.
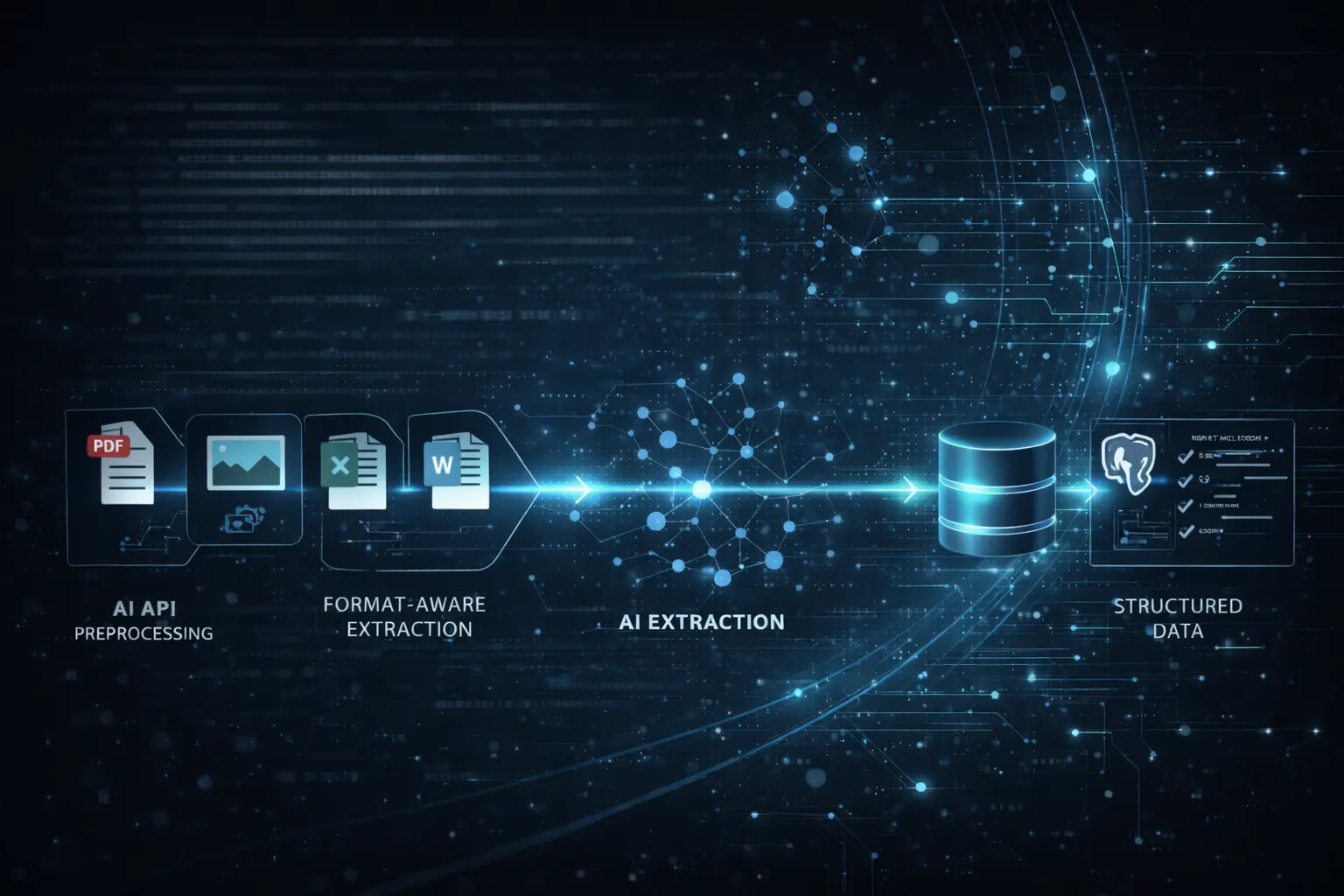
Before invoking any model, a controlled processing pipeline is built:
- Document ingestion via API
- Format detection
- Text extraction (without OCR when possible)
- Selective OCR only where needed
- Page or block segmentation
- Content normalization
This allows understanding the document before applying AI.
Context-aware prompt construction
Once the content is structured, prompts are built with explicit context control.
Instead of sending full documents:
- Only relevant pages are processed
- Context is explicitly controlled
- Input is consistently structured
This significantly improves output quality and reduces variability.
Cost optimization
Reducing the amount of data sent to the model has a direct impact on cost.
In real systems, this enables:
- Lower token consumption
- Fewer unnecessary API calls
- Scalable architectures
AI stops being the economic bottleneck.
Structured extraction and validation
Model outputs are typically generated as JSON. However, this is not the final step.
A validation layer is required:
- Field validation
- Data normalization
- Duplicate detection
- Entity matching
At this stage, PostgreSQL plays a key role as the control layer.
Integration into real systems
The real value is not extraction, but integration:
- Accounting systems
- Document management
- Internal workflows
- Process automation
AI is not the goal. It is one component of a broader system.
Conclusion
Success in document AI projects does not depend on the model itself, but on the system design around it.
A well-defined pipeline enables control, cost efficiency, and reliable results.
AI does not replace the system. It complements it.