El error más común en proyectos de inteligencia artificial aplicada a documentos es asumir que el problema consiste en “leer” el documento.
OCR, parsing automático o envío directo del archivo a un modelo de lenguaje suelen ser las primeras soluciones que se plantean. Sin embargo, en sistemas reales, ese enfoque es insuficiente y en muchos casos incorrecto.
El problema no es leer documentos. El problema es convertirlos en datos fiables, estructurados y utilizables dentro de un sistema.
El reto real: documentos heterogéneos
En entornos reales, los documentos no siguen un único formato ni una estructura estable. En un mismo flujo pueden coexistir:
- PDFs nativos con texto estructurado
- PDFs escaneados sin capa de texto
- Imágenes sueltas
- Archivos Excel con estructura variable
- Documentos Word con contenido semiestructurado
Aplicar un único enfoque a todos estos formatos genera errores, pérdida de contexto y un coste innecesario.
Por qué fallan muchos enfoques de IA documental
Un patrón habitual es enviar directamente el documento completo a un modelo de lenguaje esperando un JSON estructurado como salida.
Este enfoque presenta varios problemas:
- Coste elevado por volumen de tokens
- Pérdida de control sobre qué información se está analizando
- Resultados inconsistentes según el documento
- Dificultad para depurar errores
La IA se utiliza como una “caja negra”, lo que limita la capacidad de construir sistemas fiables.
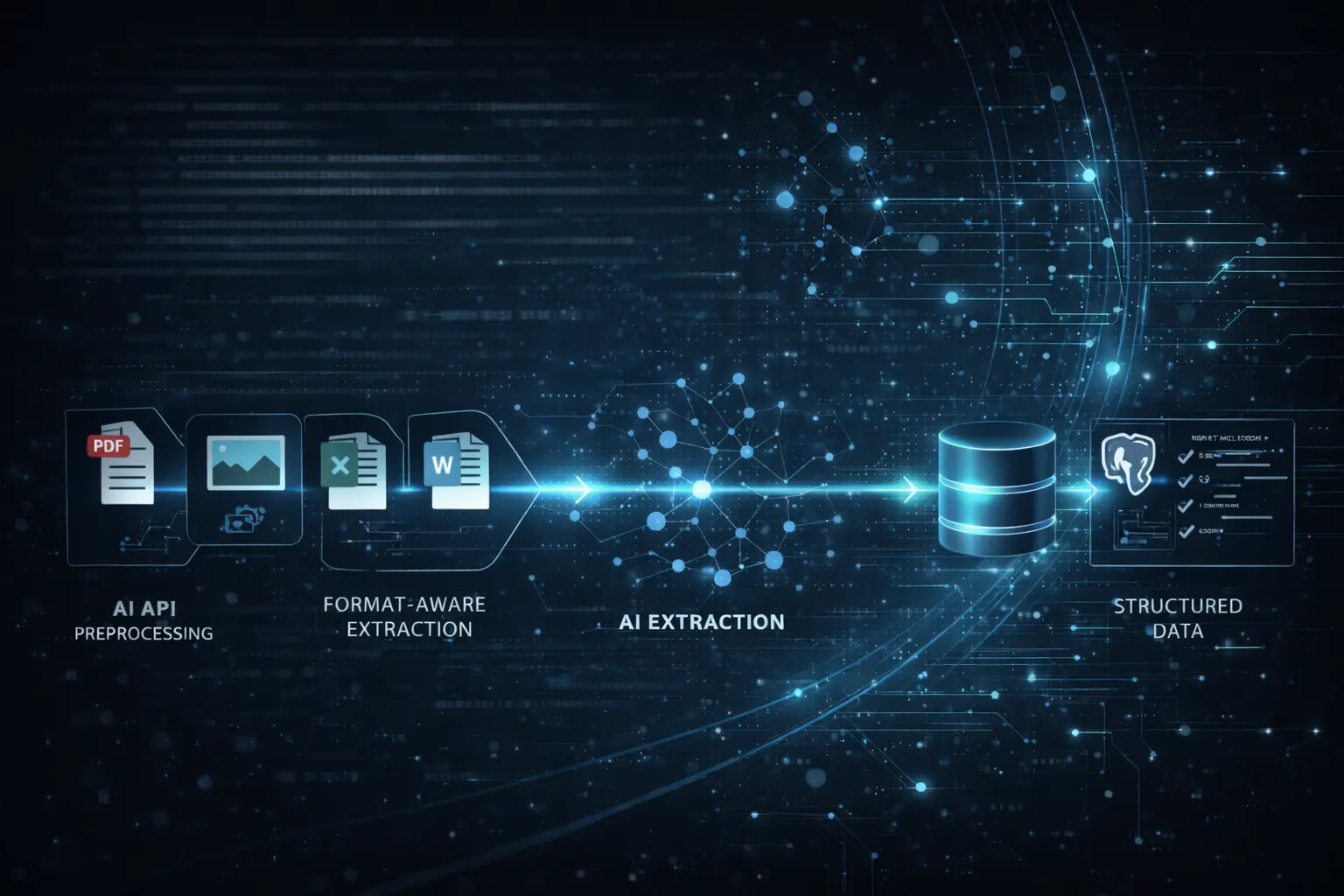
Un enfoque basado en pipeline
En Intercyd trabajamos con un enfoque diferente: la IA no es el primer paso, es el último.
Antes de invocar cualquier modelo, se construye un pipeline de procesamiento controlado:
- Recepción del documento (API propia)
- Detección de tipo y formato
- Extracción de texto (sin OCR si no es necesario)
- OCR selectivo solo en páginas o zonas concretas
- Segmentación por páginas o bloques lógicos
- Normalización del contenido
Este proceso permite entender el documento antes de aplicar inteligencia artificial.
Construcción de prompts con contexto controlado
Una vez estructurado el contenido, el siguiente paso es construir prompts específicos para el modelo.
En lugar de enviar el documento completo:
- Se envían solo las páginas relevantes
- Se controla explícitamente el contexto
- Se estructura la entrada de forma consistente
Esto mejora significativamente la calidad de las respuestas y reduce la variabilidad del modelo.
Optimización de costes
Reducir el volumen de información enviada al modelo tiene un impacto directo en los costes.
En sistemas reales, este enfoque permite:
- Reducir consumo de tokens
- Minimizar llamadas innecesarias
- Escalar el sistema de forma eficiente
La IA deja de ser el cuello de botella económico del sistema.
Extracción estructurada y validación
El resultado del modelo suele generarse en formato JSON. Sin embargo, ese JSON no es el final del proceso.
Es necesario aplicar una capa adicional de control:
- Validación de campos
- Normalización de datos
- Detección de duplicados
- Relación con entidades existentes
En este punto, PostgreSQL vuelve a ser clave como capa de lógica y control.
Integración con sistemas reales
El valor real no está en extraer datos, sino en integrarlos dentro de un sistema:
- Contabilidad
- Gestión documental
- Procesos internos
- Automatización de flujos
La IA no es un fin, es un componente dentro de un sistema más amplio.
Conclusión
El éxito en proyectos de IA documental no depende del modelo utilizado, sino de cómo se diseña el sistema que lo rodea.
Un pipeline bien definido permite controlar el contexto, reducir costes y obtener resultados fiables.
La inteligencia artificial no sustituye al sistema. Lo complementa.