Most systems start solving search with a simple LIKE. It is fast, easy to implement, and works for very basic use cases.
The problem appears as systems grow. Users make typos, use different terms, or simply do not remember the exact text.
At that point, search stops being trivial and becomes a core component of the system.
The key is understanding that there is no single solution, but a natural evolution of techniques, each solving a different problem.
LIKE: the starting point
LIKE or ILIKE allows matching exact or partial text.
It works in controlled scenarios but has clear limitations:
- No understanding of language
- No handling of variations or synonyms
- No tolerance to typos
It is a valid starting point, but insufficient for real systems.
Full Text Search: understanding language
PostgreSQL includes a full text search system that works at a linguistic level.
Instead of comparing full strings, text is broken into words, irrelevant terms are removed, and word roots are considered.
This enables:
- Relevance-based search
- Ignoring common words
- Handling word variations
Combined with normalization techniques such as accent removal, it becomes much more robust.
For many use cases, this layer is already enough.
Trigrams: handling typos
When users make mistakes or matches are not exact, textual similarity becomes important.
Trigrams compare text based on fragments, detecting similarity even with errors.
This is especially useful for:
- Names
- Addresses
- Autocomplete
It does not understand meaning, but it understands similarity.
Embeddings: understanding meaning
When the challenge is not how text is written but what it means, a different approach is needed.
Embeddings represent text as numerical vectors that capture meaning.
This makes it possible to:
- Search by intent
- Find related content without shared words
- Work flexibly with natural language
At this stage, search becomes semantic.
The common mistake: choosing one approach
A common mistake is trying to solve all search problems with a single technique.
Some systems stay at LIKE or full text search and fail in real scenarios. Others jump directly to embeddings, adding unnecessary complexity and cost.
Both approaches are incomplete.
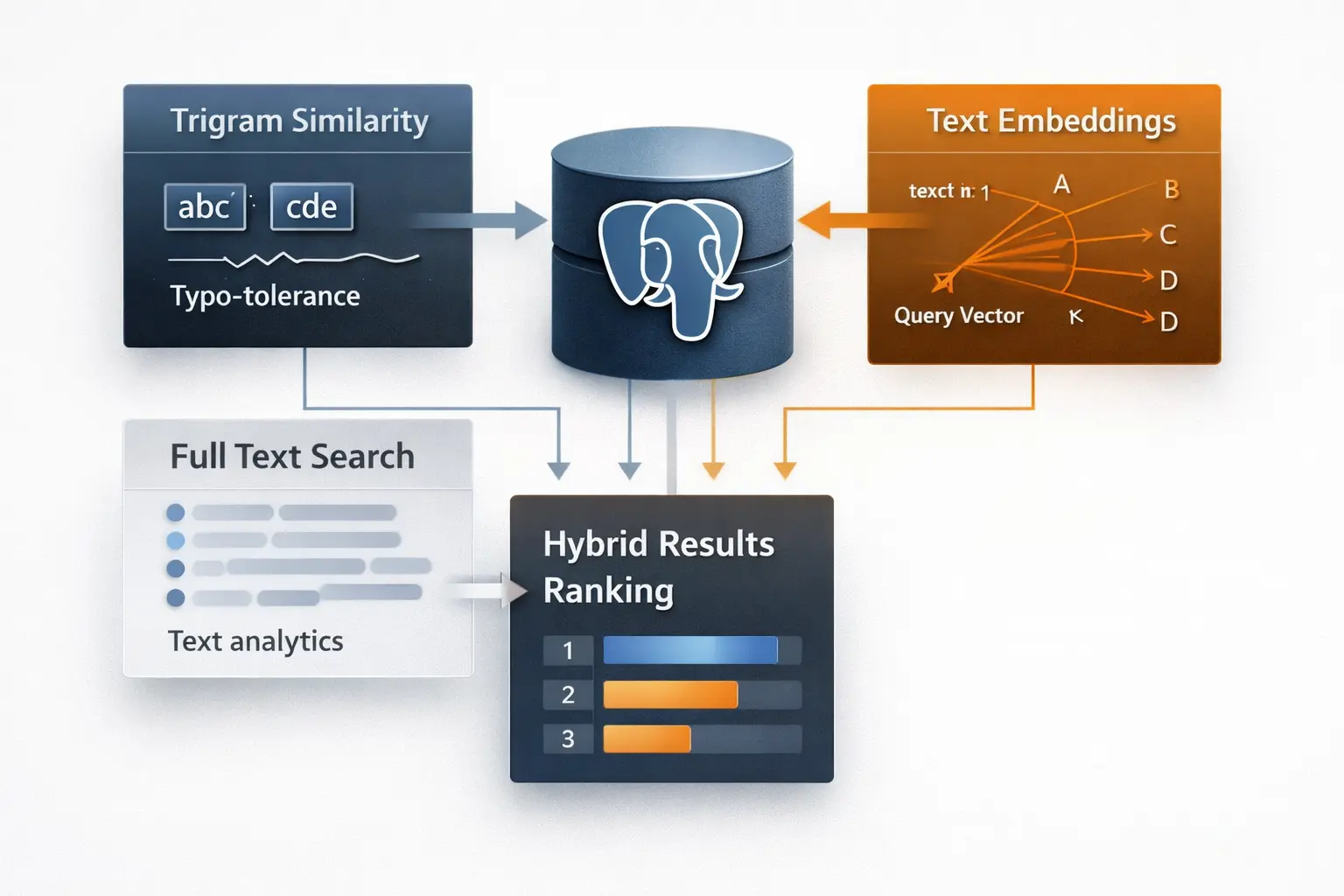
A hybrid approach
The most effective systems combine multiple techniques, each providing a different signal.
- Full text search provides linguistic relevance
- Trigrams provide textual similarity
- Embeddings provide semantic understanding
Instead of choosing one, they are combined.
The result is a system capable of:
- Understanding user input
- Tolerating errors
- Interpreting intent
The importance of balance
Not all searches require the same approach.
Depending on the context, different techniques should have more weight:
- Document search relies more on language
- Names or addresses rely more on similarity
- Open queries rely more on semantics
The goal is not to apply more technology, but the right one.
PostgreSQL as a search engine
There is a common assumption that advanced search requires external systems from the start.
However, PostgreSQL already provides enough capabilities to build advanced search systems:
- Linguistic search
- Text similarity
- Vector support
This reduces complexity, keeps systems consistent, and avoids unnecessary dependencies.
Conclusion
Text search is not a single problem but a combination of different ones.
Understanding this evolution allows building more accurate, robust, and efficient systems.
PostgreSQL is not just a database. Properly used, it can be the core of an advanced search system.