La mayoría de sistemas comienzan resolviendo las búsquedas con un simple LIKE. Es una solución rápida, fácil de implementar y suficiente para casos muy básicos.
El problema aparece cuando el sistema crece. Los usuarios cometen errores al escribir, utilizan términos distintos para referirse a lo mismo o simplemente no recuerdan el texto exacto.
En ese momento, la búsqueda deja de ser un problema trivial y pasa a ser un componente clave del sistema.
Lo importante es entender que no existe una única solución, sino una evolución natural de técnicas, cada una diseñada para resolver un tipo de problema distinto.
LIKE: el punto de partida
El uso de LIKE o ILIKE permite encontrar coincidencias exactas o parciales dentro de un texto.
Es útil en escenarios muy controlados, pero tiene limitaciones claras:
- No entiende el lenguaje
- No gestiona variaciones ni sinónimos
- No tolera errores tipográficos
Es una solución válida como punto de partida, pero insuficiente en sistemas reales.
Full Text Search: entender el lenguaje
PostgreSQL incorpora un sistema de búsqueda de texto completo que permite trabajar a nivel lingüístico.
En lugar de comparar cadenas completas, el texto se descompone en palabras, se eliminan términos irrelevantes y se tiene en cuenta la raíz de cada palabra.
Esto permite:
- Buscar por relevancia
- Ignorar palabras comunes
- Detectar variaciones de una misma palabra
Además, combinado con técnicas de normalización como la eliminación de acentos, se obtiene un sistema mucho más robusto.
Para muchos casos de uso, esta capa ya ofrece resultados de alta calidad.
Trigramas: tolerancia a errores
Cuando los usuarios no escriben correctamente o las coincidencias no son exactas, entra en juego la similitud textual.
Los trigramas permiten comparar textos en función de fragmentos, detectando similitudes incluso cuando hay errores.
Este enfoque es especialmente útil en:
- Búsqueda de nombres
- Direcciones
- Autocompletado
No entiende el significado del texto, pero sí cómo de parecido es.
Embeddings: entender el significado
Cuando el problema no es cómo está escrito el texto, sino qué significa, es necesario ir más allá.
Los embeddings permiten representar el texto como vectores numéricos que capturan su significado.
Esto hace posible:
- Buscar por intención
- Encontrar contenido relacionado aunque no comparta palabras
- Trabajar con lenguaje natural de forma flexible
En este punto, la búsqueda deja de ser literal y pasa a ser semántica.
El error habitual: elegir una sola técnica
Un error frecuente es intentar resolver todas las búsquedas con una única herramienta.
Algunos sistemas se quedan en LIKE o Full Text Search y no cubren casos reales. Otros saltan directamente a embeddings, añadiendo complejidad y coste innecesario.
Ambos enfoques son incompletos.
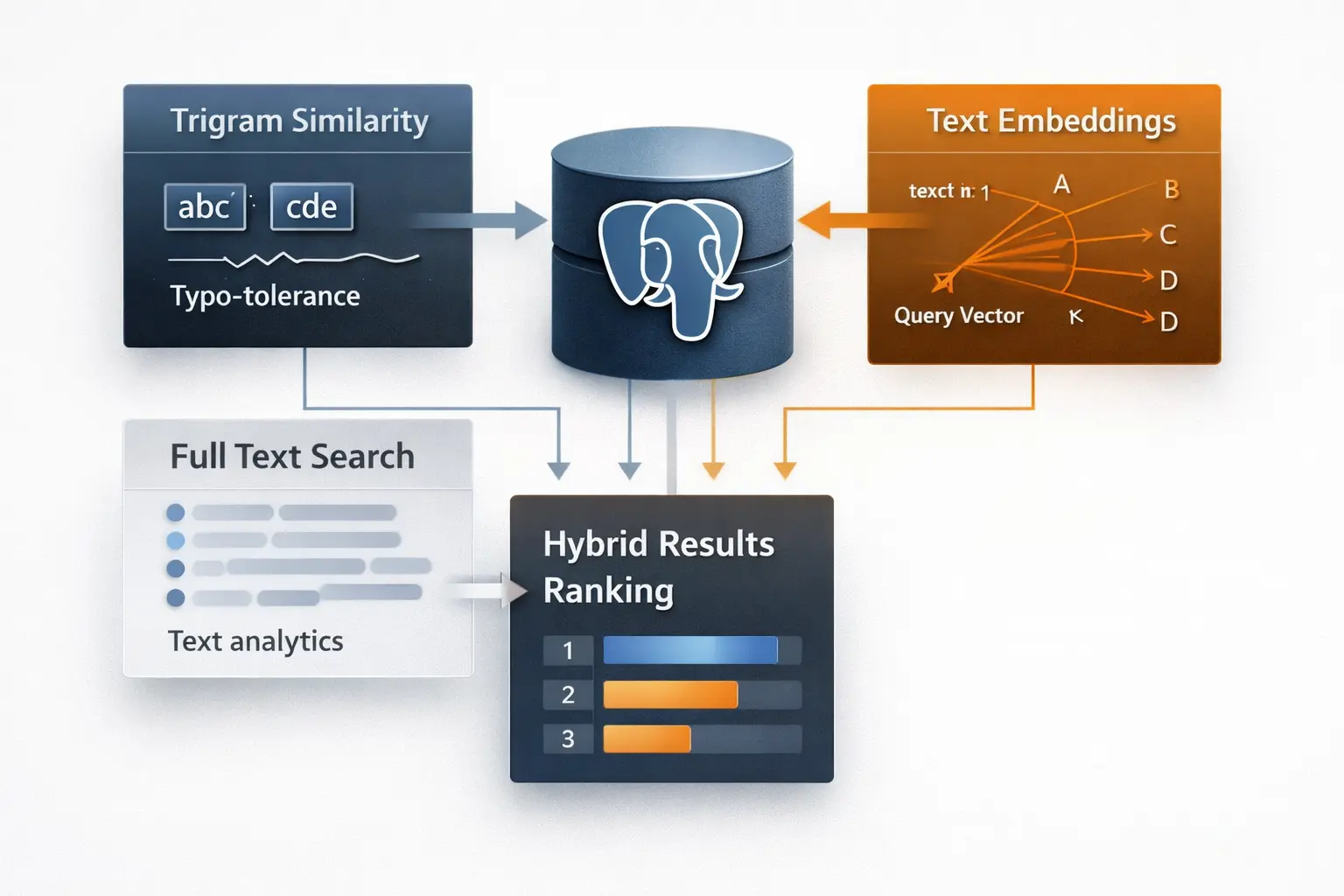
Un enfoque híbrido
Los sistemas de búsqueda más eficaces combinan varias técnicas, cada una aportando una señal distinta.
- El Full Text Search aporta relevancia lingüística
- Los trigramas aportan similitud textual
- Los embeddings aportan comprensión semántica
En lugar de elegir una, se combinan.
El resultado es un sistema capaz de:
- Entender lo que el usuario escribe
- Tolerar errores
- Interpretar la intención
La importancia del equilibrio
No todas las búsquedas necesitan el mismo enfoque.
Dependiendo del contexto, se puede dar más peso a una técnica u otra:
- En búsquedas documentales, el lenguaje es clave
- En nombres o direcciones, la similitud textual es más importante
- En búsquedas abiertas, la semántica cobra mayor relevancia
El objetivo no es aplicar más tecnología, sino aplicar la adecuada en cada caso.
PostgreSQL como motor de búsqueda
Una idea extendida es que para implementar búsquedas avanzadas es necesario introducir sistemas externos desde el principio.
Sin embargo, PostgreSQL ya incorpora capacidades suficientes para construir sistemas de búsqueda avanzados:
- Búsqueda lingüística
- Similitud textual
- Soporte para vectores
Esto permite reducir complejidad, mantener la coherencia del sistema y evitar dependencias innecesarias.
Conclusión
La búsqueda de texto no es un problema único, sino una combinación de problemas distintos.
Entender esta evolución permite construir sistemas más precisos, robustos y eficientes.
PostgreSQL no es solo una base de datos. Bien utilizado, puede ser el núcleo de un sistema de búsqueda avanzado.